
 キュウゾウ
キュウゾウ
・プログラムを1行も書かなくてもAIの画像認識を実行できる方法がある
・試しに超サイヤ人の各形態を画像認識させてみた
・駆け出しAIエンジニアは実行までできたのか?画像認識の精度はどうだった?
「プログラムを1行も書かずに機械学習(画像認識)を体験できる!」という情報をネットで見つけたので、駆け出しAIエンジニアの身として勉強の為にやってみました!
具体的にやってみたことは、
- 孫悟空の「超サイヤ人、超サイヤ人3、超サイヤ人ゴッド、超サイヤ人ゴッド超サイヤ人」の4種類の画像を各100枚をめどに集める
- 集めた画像をTensorFlowに学習させる
- 例えば、上記で使わなかった「超サイヤ人3」の画像を与えてみた時に、上のどの形態と判断するかテストする

左から(1)超サイヤ人、(2)超サイヤ人3、(3)超サイヤ人ゴッド[赤髪]、(4)超サイヤ人ゴッド超サイヤ人[青髪]
キュウゾウ
超サイヤ人2は1と違いがわかりづらいので省いて、GT版に出てくる超サイヤ人4等は判別が複雑になるので省きました!
そして、やってみた感想は、、、
- AI初心者には学べることが多かった!
- 判別の精度はイマイチなので遊びの範囲で
難易度的にはPythonもしくはプログラミングをちょっとかじったことがあれば、Googleで調べながら実行できてしまうレベルだと思います。
初心者の私がつまづいた点もこのページにまとめてますので、エラー時等の参考になれば幸いです。
TensorFlowの準備
今回の画像認識はGoogleが提供しているTensorFlowというライブラリを使います。
ここではインストールについての説明は省きたいので、TensorFlowを使ったことない方はネットで検索して自力でインストールしてみてください!
私の場合、Windows版Anaconda経由でTensorFlowの環境構築をして使っています。
tensorflow-hubも必要
既にTensorFlowが使える状態になっている方でも、tensorflow-hubはインストールされてないかもしれません。
私は入ってなかったので、ターミナルから下記コマンドを実行しました。
pip install tensorflow-hubTensorFlowのバージョンに注意
この先の実行時の話になりますが、私のTensorFlowバージョン1.4だと実行時にエラーは出ませんでした。
ただ知人のエンジニアがTensorFlow2.0系をインストールして実行したところ、エラーになりました。
1.4まで下げたところエラーが出なくなったので、これからインストールする方は1.4以下を推奨します。
Googleイメージから超サイヤ人の画像を収集
機械学習の画像認識には大量の画像データが必要になるので、まずは画像集めから始めます!
大量と言っても、今回は遊びなので、
- 超サイヤ人
- 超サイヤ人3
- 超サイヤ人ゴッド
- 超サイヤ人ゴッド超サイヤ人
Googleで検索して1枚1枚手動でダウンロードして集めるのも良いですが、Pythonを使って一気にダウンロードできる方法があるらしいので、今回はそれを真似してやってみました!
ここでもプログラミングは一切不要で、ターミナルからコマンドを実行するだけでした。
さっそく「超サイヤ人」の画像を集める時を例に実行していきたいと思います!
まずはターミナルを開いて下記コマンドを実行、
pip install google_images_download続いてcdコマンドでダウンロードしたいフォルダに移動して、下記コマンドを実行、
googleimagesdownload -k '超サイヤ人'
すると、上のような感じで超サイヤ人の画像がフォルダにダウンロードされます。
ちなみに、このコマンド1回で100枚の画像をダウンロードしようとしてくれます。
エラーになった分は弾かれますので、今回は92枚の画像がダウンロードできました。
不要な画像を削除したり、精度が上がるように加工した
超サイヤ人の画像をダウンロードしたはずなのに、超サイヤ人ゴッドの画像が混じっていたり同じ画像がダウンロードされていたりするので、不要な画像は削除しました。
また文字(テキスト)が邪魔だったり、他のキャラクターが一緒に入り込んでいる画像も多かったので、画像編集ソフトで切り取りなどして加工しました。
ここは自動化できず人間による手作業が必要で、とても面倒です。
AI時代の新たな労働問題を身をもって体験できたような気がしました。
他の超サイヤ人の形態も同様にして画像収集
googleimagesdownload -k '超サイヤ人3'のようにして他の超サイヤ人の形態も画像をダウンロードしていきます。
各形態の画像は、それぞれダウンロードするフォルダを分けてあります。
そして、集めた画像を削除・加工していったら、最終的には下記の枚数に落ち着きました。
- 超サイヤ人:58枚
- 超サイヤ人3:56枚
- 超サイヤ人ゴッド:53枚
- 超サイヤ人ゴッド超サイヤ人:83枚
各100枚をめどに集め始めたのですが、実際はかなり減ってしまいました。
今回は遊びなのでこの枚数で進めていくことにします。
ちなみに、各画像ファイルの名前はダウンロードしたままでOKで、リネームしないでも特に問題ありませんでした。
Githubから2つのファイルをダウンロード
上記のリンクをクリックして「Raw」という箇所を右クリックするとダウンロードできます。
ソースを丸々コピペして自分でファイルを作成しても同じです。
キュウゾウ
フォルダ構成はこんな感じ
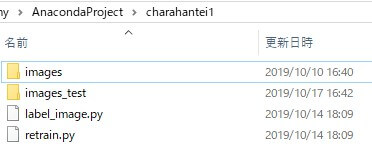
普段TensorFlowを使っているフォルダの配下に、今回用に「charahantei1」というフォルダを作り、その中に、
- images
- images_test
- retrain.py
- label_image.py
imagesフォルダの中には下記のように「超サイヤ人の各形態ごとの画像フォルダ」があります。
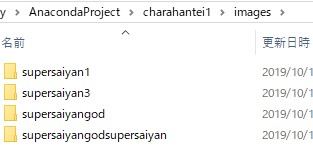
この画像フォルダ名が日本語だとエラーになるみたいなので、「supersaiyan1」のように半角英数にしています。
「supersaiyan1」フォルダの中には超サイヤ人の画像が58枚入っています。
「images_test」フォルダの中はこの段階では何も入ってなくてOKです!
これで準備は完了です。
retrain.pyを実行して画像データを学習させる
python retrain.py \
--bottleneck_dir=bottlenecks \
--how_many_training_steps=200 \
--model_dir=inception \
--summaries_dir=training_summaries/basic \
--output_graph=retrained_graph.pb \
--output_labels=retrained_labels.txt \
--image_dir=images
ターミナルを開いて上記コマンドを実行します。
もし画像を置いてあるフォルダ名が私と違うなら、一番下の「images」の部分を変える必要があります。
単項演算子がエラーが出る場合
私の場合windows環境だからか、上のようにコマンドを入力すると「単項演算子 ‘–‘の後に式が存在しません」というエラーが出てしまいました。
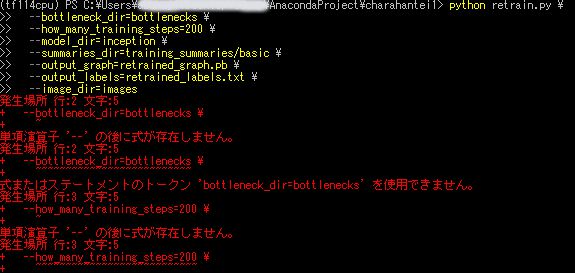
コマンドを改行しているのが原因らしく、
python retrain.py --bottleneck_dir=bottlenecks --how_many_training_steps=200 --model_dir=inception --summaries_dir=training_summaries/basic --output_graph=retrained_graph.pb --output_labels=retrained_labels.txt --image_dir=imagesのように1行にして実行したら上手くいきました!
エラーもなく実行できたら
この段階で「TensorFlowが超サイヤ人の各形態を、画像認識を使って学習できた」ということになります!
自分が画像認識をやっているなんてテンション上がりますね。
次は本当に学習できているのかを確認する為に、「label_image.py」に超サイヤ人のどれかの形態の画像を1枚送って、「正しく形態を判別できるか?」をテストします。
label_image.pyに超サイヤ人の画像を送って判別させる
python label_image.py \
--graph=retrained_graph.pb \
--labels=retrained_labels.txt \
--output_layer=final_result \
--image=images_test/hanbetu1.jpg \
--input_layer=Placeholderimages_testフォルダの中にhanbetu1.jpgという超サイヤ人の画像を入れた場合のコマンドです。
先ほどと同じく私の場合エラーが出るので、下記のように改行せずに実行しました。
python label_image.py --graph=retrained_graph.pb --labels=retrained_labels.txt --output_layer=final_result --image=images_test/hanbetu1.jpg --input_layer=Placeholderimagesフォルダの中に入れたのは学習用の画像なので、同じ画像を使ってしまうと精度が良くなってしまう可能性があります。
私たちの身近な例で言うと「練習問題と試験問題が同じ」というような感じです。
判別1:超サイヤ人の画像で試してみた

まずは普通の超サイヤ人の画像を送ってみました。
すると結果は、
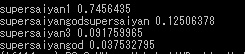
- 超サイヤ人:74%
- 超サイヤ人ゴッド超サイヤ人:12%
- 超サイヤ人3:9%
- 超サイヤ人ゴッド:3%
のようになり上手く判定できてました!
超サイヤ人判別機として期待できそうです!
判別2:超サイヤ人3

続いて超サイヤ人3の画像を送ってみました。
髪が長いのがわかりやすい画像をあえて選びましたが結果は、、
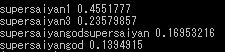
- 超サイヤ人:45%
- 超サイヤ人3:23%
- 超サイヤ人ゴッド超サイヤ人:16%
- 超サイヤ人ゴッド:13%
3ではなく、普通の超サイヤ人である確率を一番高く示していますね。
う~ん、髪の長さを上手く判別できていないようです。
判別3:超サイヤ人ゴッド

次は超サイヤ人ゴッドの画像を送ってみました。
髪が赤いのが特徴です。
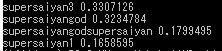
- 超サイヤ人3:33%
- 超サイヤ人ゴッド:32%
- 超サイヤ人ゴッド超サイヤ人:17%
- 超サイヤ人:16%
なぜか超サイヤ人3という判定に…
ただ1%差で正解の超サイヤ人ゴッドを示しています。
他のだったら髪型が似てるから理解できるのですが、よりによって超サイヤ人3を選んでしまうとはちょっと理解が追いつきません。
判別4:超サイヤ人ゴッド超サイヤ人

最後に超サイヤ人ゴッド超サイヤ人の画像を送ってみました。
髪が青色なので、そこを上手く判別してくれると良いのですが。
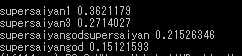
- 超サイヤ人:36%
- 超サイヤ人3:23%
- 超サイヤ人ゴッド超サイヤ人:21%
- 超サイヤ人ゴッド:15%
1番目に超サイヤ人、2番目に超サイヤ人3となり、こうなってくるともはや意味不明です。
精度はどうだった?考察・まとめ
この後も実験を繰り返し30枚ほど判別させてみたところ「判別4」のような結果になることが多く、全体的に精度的にはいまいちな結果に終わりました。
実行前は「髪の色の違いくらいは正確に判別してくれるのかな」と思っていましたが、そこはかなり予想が外れました。
例えば、もし「髪の色については正確に判別できて髪型については精度が悪い」というような傾向が出ていれば、機械学習の画像認識の癖を少しはつかめたのかもしれません。
今回は傾向が出ていなかったので、機械学習の何かをつかむまでには至りませんでした!
- 学習モデルが悪いのか
- 画像データの質が悪いのか、量が少ないのか
ただAIエンジニア駆け出しの身としては、実行しただけでも得るものはたくさんありました。
次回は他で習った学習モデルを真似して自分でプログラムを書いてみて、同じ画像データで試したら精度が上がるのか?というようなことを試してみたいと思います!

